
Now that Digital Lethargia and the Diglet RSS Reader have been live for a while, I figured there was a need to break up the content that gets loaded into pages or something similar. This will help keep the scroll length and the memory usage of the browser down. I also noticed that performance of fetching unread RSS articles was starting to suffer, and retrieving fewer rows at a time could help with that, although that problem was better helped by creating some extra indices on the databases as you will read below.
Let's start with pagination, which turns out to be a lot more complicated than you would think. It is especially hard to do on data that is coming in from multiple sources, and is mixed together into one view. I spent a long time trying to get some traditional methods to work, as well as some add-ons to GORM and GoLang in general, but got nowhere with it. Another method would be to do the dynamic loading that a lot of social media sites use, where new content is automatically loaded as you scroll towards the bottom of the page. This is a behaviour that I really do not like, as it gets in the way of getting to links at the bottom of the page (where a lot of RSS feed links are!) and I just don't like the idea of constantly chasing the end. The method that ended up working for me in the end is kind of a hybrid of this dynamic model and Cursor Pagination. So lets start with defining the two common methods of paginating results from a database:
Limit/Offset Pagination
This is the most common and basic method of pagination. It basically uses the formula of "Give me a list of items starting at the row number equal to the page number multiplied by the number of items per page". As you serve out the data, your "Limit" is the number of items per page, and your "Offset" is the Limit multiplied by the page number, giving you a query like the following:
SELECT * FROM items ORDER BY date DESC OFFSET 100 LIMIT 10
This works great on smaller data sets that are fairly static, and are easily ordered. But it does not scale very well, as once the offsets start getting large, the queries have to step over all the rows that you are skipping. Also, if items are inserted or deleted, they are easily missed as someone is paging through the data and the number of rows change.
Cursor Pagination
The concepts of Cursor Pagination are similar to Limit/Offset, except that instead of just dealing with the starting row and number of rows, you are keeping track of an identifier for the last item returned. For the next page, you are querying for values greater/less than that value. From a database perspective this is much more efficient, as finding your starting point using a WHERE clause is much quicker than giving an offset of rows to skip over. Another advantage to this method is that it prevents items being missed on active/dynamic datasets. If rows are being inserted/removed while people are trying to page through them, they won't be missed because we are continuing on from the value of where we left off, instead of a static number of rows. An example of a query statement for Cursor Pagination would be:
SELECT * FROM items ORDER BY date DESC WHERE date < cursorValue LIMIT 10
While it looks very close to the original one, it will be much faster in larger datasets, but you need to keep track of the values for the cursor between loads. One of the downsides to Cursor Pagination is that it is a bit more complex, especially if you also want to be able to return to previous pages.
This is basically the method I ended up using. Since you can mark items as read or saved for later, and the fact that each feed's articles will be returned in the order of their publish date as they get added, the data being returned is fairly dynamic, and would be fairly inaccurate if I used the Limit/Offset method. While it is possible to keep track of previous pages in Cursor Pagination, the hidden read/saved items in my dataset started to make that functionality really complex and I decided to abandon "pages" of data for a method closer to the dynamic loading I mentioned earlier. Instead of automatically loading the next set of data when you scroll, I added a "Load More" button that stays at the bottom. When clicked an AJAX request uses the cursor value to return the next set of data and it dynamically gets added to the end of the page.
How to Use
By default, the page size is set to 25 items.You can change this using the dropdown at the top right:

If there are more items than that count, a "Load More" link will appear below the last article. Simply click on that link to retrieve the next set of articles. 
The sorting icon and behavior has changed a little. Click the icon ( ) at the top right to toggle the date sorting between descending (default) and ascending order.
) at the top right to toggle the date sorting between descending (default) and ascending order.
Indices
Splitting up the data into pages did help with the rendering time and memory usage in the browser, but did not help much with the loading times overall. Since I am not very experienced on the database design side I figured I had a great deal that could be improved there. I started by doing some research into creating indices in MySQL to see if that would help. An index for MySQL is basically a separately maintained BTree (in most cases) of the values you want that are kept in order to allow for faster lookups. Indices can slow down the writes of a table since it also gets updated with every INSERT, but can greatly increase the speed of lookups. There was currently no issue with write speeds in the system, so I continued.
When creating the list of articles to display for a user on the front page, the system is getting all the articles for each feed that they follow, and omitting any of them marked as read or saved by the user through a JOIN to a separate table. I assumed that this was the piece that was slowing things down the most, so I created a multi-column index on the articles table based on the feed Id, published status and publish date. I also created one on the table that keeps track of items read/saved based on the user Id and the article id. As soon as the indices were populated, the load times of the front page improved by over 5x. Success!
Changes committed since last Dev Diary
- You can now collapse the sidebar using the (
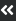 ) icon
) icon - Added social links (YouTube, Twitch, and Twitter) to menu

- Pagination implemented (See above for instructions)
- Fix for overflow on long article titles.
- Added BBS and Help pages
- Added support tickets for logged in users
- Fixed security bug with public groups
- Log cleanup job.
References
- Limit/Offset and Cursor Pagination: https://dev.to/jackmarchant/offset-and-cursor-pagination-explained-b89
- Cursor Pagination: https://medium.com/swlh/how-to-implement-cursor-pagination-like-a-pro-513140b65f32
- Indices: https://www.tutorialspoint.com/mysql/mysql-indexes.htm

One of the main features for Digital Lethargia that I planned from the start was an RSS/Atom reader/aggregator, and I have finally made some progress towards that in the past couple of weeks. Even though it is an old technology, and is nowhere near as prevalent as it once was, I still feel that it is the best way to receive the content I want, the way I want it. I am hoping that I can provide a system here that other people may actually enjoy using, giving them a method of receiving news/content from sources they pick in a way that is not filtered or tracked through the algorithms of the big social networks.
What is RSS?
Depending on which point in history you are looking at or what you are using it for, RSS can stand for Really Simple Syndication, Rich Site Summary, or RDF Site Summary. It was first designed by people at Netscape as a means for them to build channels into the My Netscape Portal, pulling in headlines from different sources. After the AOL takeover of Netscape shifted the focus, development of the RSS specification was picked up by others who disagreed on what the purpose of RSS should be. Today we are basically left with two similar standards still in use. RSS 2.0 which took on the "Really Simple Syndication" name, and the Atom Syndication format (See "The Rise and Demise of RSS" for a more detailed history).
Today RSS is probably most widely used for the distribution of podcasts, but most news sites, comics, and blogs still serve out feeds. Basically, an RSS feed is an XML file that provides a listing of headlines, summaries, and sometimes the full content from a source like a website, comic, or podcast. It provides a way for content creators to syndicate their items to people so that they can consume the content however they like. This is usually done via applications called readers/aggregators, but the format provides an easy way for any application to use.
Why is RSS "dead"?
Many people will say the rise of social networks was a big killer of RSS, and that is true to a certain extent. Things like Facebook and Twitter make a convenient place to get most of your news, while following content creators and friends at the same time. Some of my concerns with consuming content though the social networks include the privacy issues around using those services, the trust around the spread of misinformation just because things are shared by a large number of people/bots, and the fact that the algorithms of those sites are designed to feed you specific types of content just to keep you clicking more items within their ecosystem.
Another reason RSS has declined over the years is that it is not the easiest thing to understand, and has not evolved in any significant way over the years. Especially after Google shut down its' Reader app, and the major browsers dropped support, RSS became that much more inconvenient to use, and it can take a bit of hunting to find the RSS feeds for the sources you trust as they don't prominently display the feed icons anymore.
Digital Lethargia RSS
When starting work to add support for what I am calling "Remote Feeds" (RSS/Atom, others in the future) into Diglet, my plan was to use the built in XML support that GoLang has to read the files, and then do the mapping of the items myself. I did something similar in PHP for the last version of Digital Lethargia, but then I came across a library called gofeed that is still being maintained. GoFeed has removed a lot of the tedious steps I was going to have to go through myself, and if it turns out I need to write my own library for this eventually it is separated enough that I can do so without having to change much existing code.
When complete, you will be able to go to a page that shows all the feeds you are currently following, and list all the available ones you are not. Categories and filtering will be available to help narrow down the selections, and you will be able to preview the current articles within that feed. If you don't see what you are looking for, you can simply paste a link to the RSS feed of your choice to follow it. Once you follow a feed, by default, all the articles from that feed will be added to the aggregated list of articles you see on the front page, mixed in with the local Digital Lethargia content. You will be able to change this and pick which feeds get shown together vs which ones you will have to select from the navigation menu and view separately (e.g. if you don't want to see podcasts or comics on the main page, you can remove them). Remote feeds will be updated hourly, evenly spread out over each 15 minutes, and removal of old items will be done automatically. Some other features:
- Marking articles as "read". This will hide them from the list, but you can view hidden items if needed
- Marking articles as "saved". This will hide them from the list, but place them in a separate "Saved for later" feed and make them exempt from cleanup
- Ability to play podcasts right from the article. Looking into options to pop out a player to a separate tab so that you can continue browsing.
Work in Progress
Some examples of how this is working in the current development build of diglet:
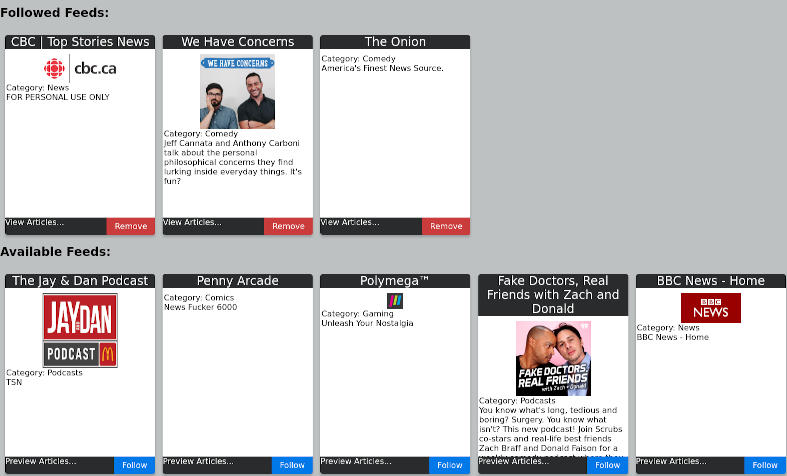
Work in progress article full view
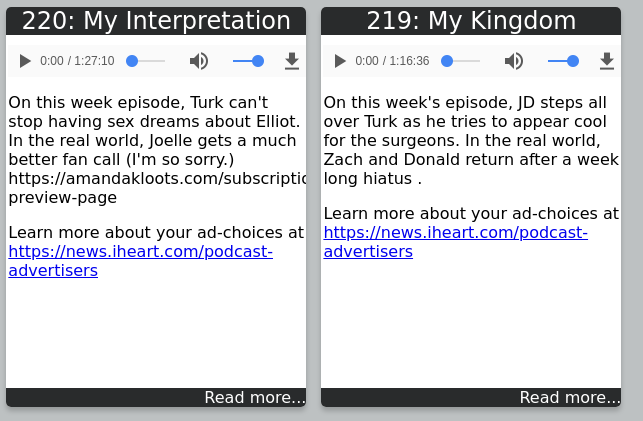
Work in progress preview card view.
References
- GoFeed: https://github.com/mmcdole/gofeed/
- The Rise and Demise of RSS: https://www.vice.com/en_us/article/a3mm4z/the-rise-and-demise-of-rss
- RSS: https://en.wikipedia.org/wiki/RSS
- Atom: https://en.wikipedia.org/wiki/Atom_(Web_standard)
- XML: https://en.wikipedia.org/wiki/XML
It didn't take long for me to break the second lesson from Dev Diary 1 about sticking to more frequent dev sessions and trying to sit down for at least 30-60 minutes a day to work on something productive for myself. But that is ok, excuses and life aside, I will use another movie quote that is helpful when you don't meet your goals or fail to stick to a plan:
Every passing minute is another chance to turn it all around

So on that note I am back working on Digital Lethargia, and thought I would just write a short Dev Diary about a couple of added features.
Content list views
For sections that have a list of items/articles, you can now choose between three views by using the buttons at the top right of the page (![]() ). Your choice will persist across your session, and will eventually persist in a user preferences table once I have a reason for people to have accounts here. There is a full view where the articles are all fully displayed, a preview view where cards showing the splash image and a snippet of the articles are displayed, and a headline view where just a list of headlines is displayed. For the preview and headline views, you can click on the title to view the full article. A "Read more..." link is also at the bottom of the preview cards.
). Your choice will persist across your session, and will eventually persist in a user preferences table once I have a reason for people to have accounts here. There is a full view where the articles are all fully displayed, a preview view where cards showing the splash image and a snippet of the articles are displayed, and a headline view where just a list of headlines is displayed. For the preview and headline views, you can click on the title to view the full article. A "Read more..." link is also at the bottom of the preview cards.
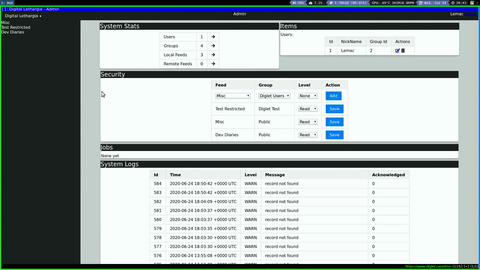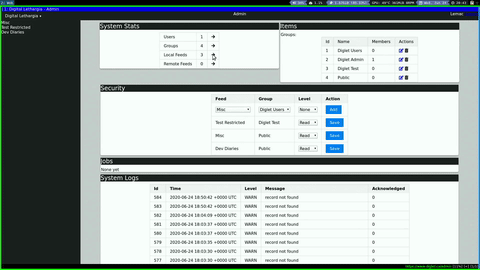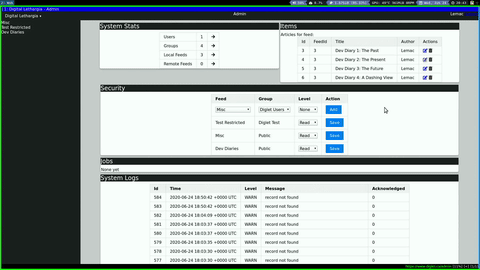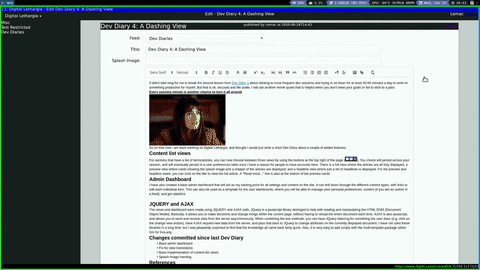
Admin Dashboard
I have also created a base admin dashboard that will act as my starting point for all settings and content on the site. It can drill down through the different content types, with links to edit each individual item. This can also be used as a template for the user dashboards, where you will be able to manage your personal preferences, content (if you are an author in a feed), and get statistics.
JQUERY and AJAX
The views and dashboard were made using JQUERY and AJAX calls. JQuery is a javascript library desinged to help with reading and manipulating the HTML DOM (Document Object Model). Basically, it allows you to make decisions and change things within the current page, without having to reload the entire document each time. AJAX is also javascript, and allows you to send and receive data from the server asynchronously. When combining the two methods, you can have JQuery listening for something the user does (e.g. click on the change view button), have AJAX request new data from the server, and pass that back to JQuery to change attributes on the currently displayed document. I have not used these libraries in a long time, but I was pleasantly surprised to find that the knowledge all came back fairly quick. Also, it is very easy to add scripts with the multi-template package within Gin for GoLang.
Changes committed since last Dev Diary
- Base admin dashboard
- Fix for view transistions
- Base implementation of content list views
- Splash Image handing
References
- JQUERY: https://jquery.com/
- AJAX: https://api.jquery.com/category/ajax/
With the past explored, and the present documented, it is time to look to future. In this entry, I will go over some of the planned features for Digital Lethargia, as well as some of the content ideas I am playing with. Of course the future is not yet written, so plans may change and new ideas may take priority.
Short Term Fixes/Additions
There are some immediate things that I have on my list to get going before I can comfortably say I have a good base to build off of. Here are some of the highlights:
Styling and Navigation
One of my biggest weaknesses is making things look good (Just ask my mirror...). I can generally move/transform data, and solve most functional problems well, but aesthetics/user experience is a difficult area for me. As you can currently see, the site doesn't look the greatest, from both a layout and a visual sense. Also, I have not done much to make the site great on mobile devices yet. It is readable, but has a lot of room for improvement. I want people to be able to switch between views as they prefer, and have things be more dynamic depending on the devices being used.
For navigation, I have a base created, but since there is only one feed with content currently, nothing has been implemented on the front end. If you are viewing this on a big enough screen right now, you can see a list of feeds you have access to in the left pane. These will eventually become clickable and serve as the context menu. At the top left is a dropdown menu that will have extra items and serve as the full menu for mobile devices. My next steps are to refresh my knowledge of JQuery to accomplish some of the more dynamic tasks, while making sure things will still work for people who have javascript disabled.
Planned work in this area:
- Selectable views in content area (e.g. Headlines, preview cards, read-more cards etc)
- Sorting options to not only show newest first
- Pagination (So that the site doesn't show all the content at once)
- Better mobile styling
General Admin and Content Creation
The general operation of the site feels fairly solid now. I have separate admin pages for security, feeds, articles etc., and they have the basic operations implemented. I would like to bring these into a more centralized admin dashboard that can perform the basic tasks for each section, give statistics, and link to the full admin pages as needed. As I write new features, I am trying to get the admin functions done at the same time to avoid having to directly manipulate the database at any time.
On the content creation side, I am currently using Quill as a WYSIWYG editor, and I am undecided about it. It is super easy to setup and use, but I am finding more items that I am writing workarounds for which is not ideal. It is fine for now but I may revisit this, especially if other people come on board to start creating articles for Digital Lethargia. Having a dashboard for authors that shows drafts, published articles, and other items is also an important thing for me to get setup.
Planned work in this area:
- Admin Dashboard
- User Dashboard
- Improve authoring experience
- autogenerate RSS feeds for the local content
Short-Medium Term Features
To try and keep things in managable chunks I have decided on two features to focus on first while completing the above improvements.
Feed Aggregation
One of the pieces I used a lot in one of the earlier revisions of Digital Lethargia was the rss feed reader. I would like to bring that back here and actually make it available to everyone in the hopes that it might be useful for others. In basic terms, a lot of sites and services publish feeds that list and links to their recent content. I want people to be able to add feeds that they follow into this site, as well as browse feeds other people have added to follow. This puts all of your news, webcomics, podcasts etc. into one place. As you read items they get hidden from your list or you can save them for later consumption. There are a few products out there that already do this, but for some reason I can never find one I really like, so maybe I can create something again that fits the bill.
Planned Features:
- Add new or follow existing feeds in the system
- Choose which feeds get blended into your main feed, and which are kept separate
- Mark items as read or saved
- Play podcasts via built-in HTML5 players
Feature Ideas to explore in the future
- Keep track of location in podcasts, allow offline saving to mobile (Seen some javascript for the location, and some possible cache options for offline, but not sure if doable)
- Add YouTube channels as feeds
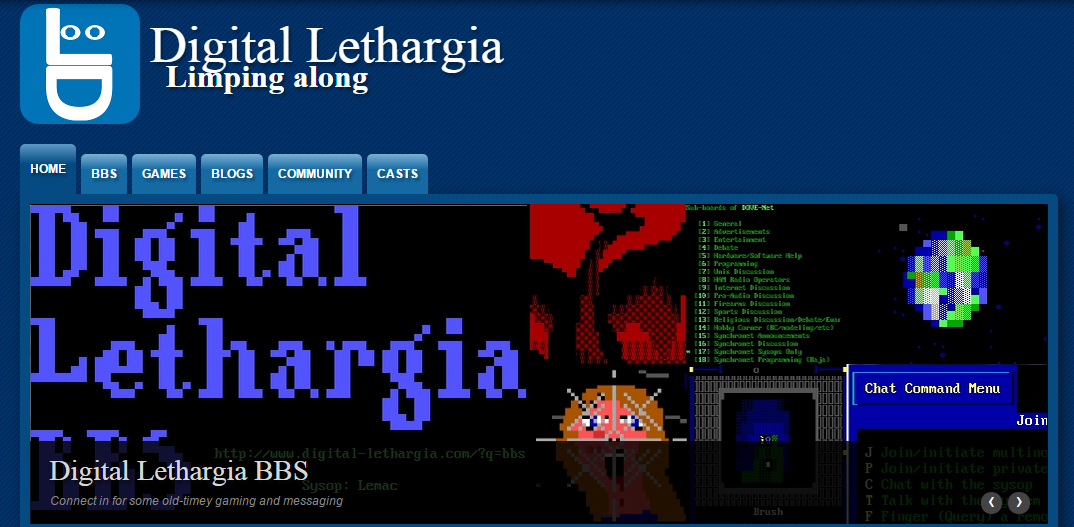
Digital Lethargia BBS

I chose to work on the BBS before SlackTicker because of the estimated size of the job. The Feed Aggregation is a fairly involved project, while I feel the BBS is a lot smaller of a job than SlackTicker, so I can pair up a larger and smaller project togeher. The main point of the BBS is nostalgia, playing the old games we did back in junior high, and playing around with some fun messaging options like DoveNet. I want to have the BBS running out of a Docker container to keep the telnet access isolated, as well as provide an easy way to copy the system for testing changes etc.
Planned Features:
- Selection of the usual games (LORD, Usurper, BRE etc)
- Have the scores/stats integrated into the website so that you can view standings at any time.
- Provide an integrated HTML5 terminal so that you can login from the browser or your favorite client
Medium-Long Term Features
There are of course an endless amount of items and ideas I could work on, but there is only so much time. However there are some ideas I know that I would like to get to.
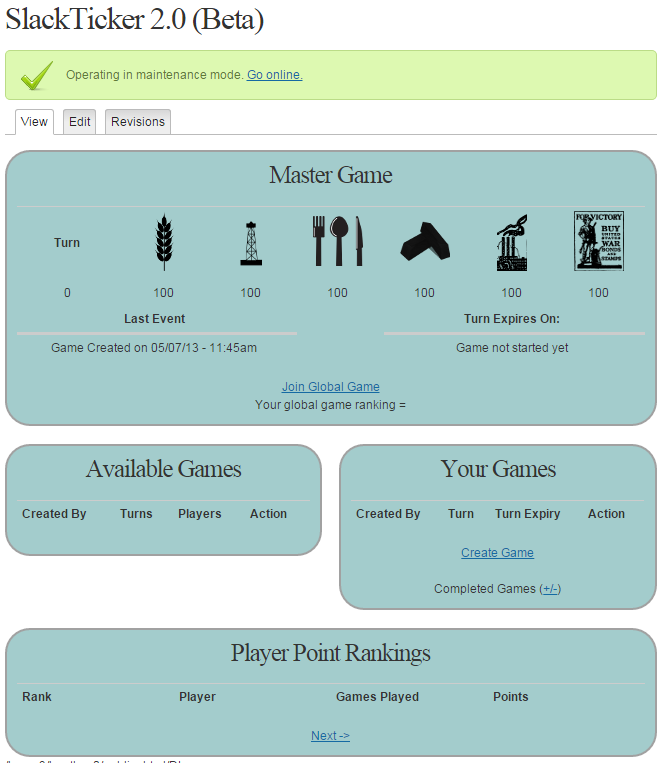
SlackTicker 2.0
I had a beta version of SlackTicker 2.0 written in PHP and runninng on a previous revision of Digital Lethargia. Porting this over to Golang should not be too complicated but will take some time. Here were the features of that version that may or may not change as I rewrite it:
- Global long term game that everyone is a part of and can take one turn per day
- Smaller games that you can setup or join with other people, that either allow one turn per day, or more if everyone has already completed their turn.
- Winning the smaller games can earn you cash or bonuses in the global game.
- Leaderboards for points earned in smaller games.
Fully Featured API
Digital Lethargia is currently being written with an API in mind. By keeping the model and security functions separate from the front end handlers, I can reuse most of the code for the API and just have a different set of handlers. This opens up the possibility to write other Apps and services based on Digital Lethargia.
Possible features:
- Fully RESTful interface
- Possible mobile apps
- NCurses terminal apps (I love NCurses based apps and use them a lot)
Misc Ideas
- Discord server associated with Digital Lethargia (the channels and discussions there could act like a forum)
Content Ideas
Since the base system currently works well as a blogging system, it would be nice to also start producing some local content for Digital Lethargia. My personal goals in creating content would be to start flexing my tired old writing muscles, to provide an additional creative outlet to coding, and to learn some new skills. One new skill I am interested in is video editing, so I would like some of the content to have a video component to it while staying text friendly overall. I would also like to bring other friends to create their own content as well since the system supports different feeds and security groups. Here are three initial categories I am thinking of:
Dev Diaries
The Dev Diaries will continue, but will mostly be shorter and more focused from here on out (I hope...). I would like to pick a specific problem or feature in each one, describe how I tackled it, and the lessons learned while doing so.
Sysadmin and Tech tips
My day job in IT and my hobbies in computing/linux provide me lots of opportunities to problem solve and play with new systems. I am going to try and capture certain things I find interesting and pass them along. This should also help develop my technical writing skills to feed back into my career.
Gaming
I have put together a halfway decent video came and console collection over the years (As shown in the images below). I think putting together content based on that will provide a good way of cataloging it. We could probably even try some live streams around the items currently being played for recorded/written content. I know that retro-gaming content on the internet is not exactly an original idea, but maybe I can come up with something interesting.



Thanks to everyone for reading. Hopefully you are looking forward to some of these features.
Changes committed since last Dev Diary
- Fixed overflow on mobile for code blocks
- Group admin handlers
- User admin handlers
- Security admin handlers
Now that we have explored the past, let's go through some of the platforms and tools I am using for this revision of the site. I will try to explain the reasoning behind the decisions as well as lessons learned along the way. The main goals for me on the technology side was to start flexing the old programming muscle again (I do a lot of scripting at work which helps, but is not quite the same), and to learn some new skills that will be useful for both my career and personal projects.
Golang
I think my experience with C programming is what drew me to Go. My mindset seems to fit better with statically typed languages in a structured vs object oriented style. Go aims to be more readable than C/C++ as well, and while some scripting languages may be even more readable, I find Go quite easy to follow. The other nice part of Go is the large amount of built-in packages you can use to accomplish most tasks, as well as a large selection of community packages available to do almost anything. A good example of the power built into Go is how easy it is to setup a basic web server (Example from yourbasic.org):
package main
import (
"fmt"
"net/http"
)
func main() {
http.HandleFunc("/", HelloServer)
http.ListenAndServe(":8080", nil)
}
func HelloServer(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hello, %s!", r.URL.Path[1:])
}
While using 3rd party packages adds external dependancies and some risk to your project, they can save you a lot of time and effort that would be spent writing every task yourself. Here are a couple that I have used:
Gin
Gin is a web framework for Go that claims to be 40 times faster than the built in one. I mostly chose it for the ease of use and extra features that you can plug into it. It has modules to easily handle sessions, SSL encryption, templating and more. I especially like the multitemplate module, where you can stack template files together and it automatically combines them into the served page, dynamically filling in content from passed in variables. This allows the reuse of common files across your templates. Here is an example:
renderer := multitemplate.NewRenderer()
renderer.AddFromFiles("front", "templates/base.html",
"templates/sidebar.html",
"templates/base.css",
"templates/base.js",
"templates/front.html")
GORM
GORM has truly been a time saver for me. It is an Object-Relational Mapping (ORM) library for Go. One of the biggest pains in creating systems is properly moving data back and forth between your backend data store (usually a database) and your user interface. You have to create structures or objects within your application, and create functions that convert those data types into the proper queries to read and write data to/from the database. An ORM library handles the data mapping and connections for you, allowing you to only deal with the structures themselves. GORM is the first library of this type I have used, so I am not sure how it compares, but I am very happy with the results so far. All I have to do is define a structure with all the fields I want (e.g. I have a struct type called Article with various fields), and pass it to GORM's AutoMigrate function. When the application starts up, GORM checks to see if there is a table in your database for each of the structs, and creates it if it doesn't exist. Similary you just populate one of the structures and call GORM's Create or Save functions to add or modify data. It also handles your associations (has many, many to many etc.) and takes care of primary/foreign keys for you, with the option of manually declaring them as well. One other great feature is that it can connect to many different backends, allowing you to switch systems without changing your code. I use this for testing. When testing/developing locally, I have GORM create an SQLite file on my local disk and populate it, while the staging or production versions connect to a MySQL database.
Auth0
Security and account management is always a tough thing to do well. I did not want to be storing any passwords or sensitive information within my system. I am just not enough of an expert to feel comfortable against attacks, so I don't want to keep anything more than an email address and preferences. After trying a couple different approaches I decided on Auth0 for identity management. They have a good free tier for smaller projects, and provide easy to follow examples for using their service in Go from both a web server and api service perspective. When this site eventually has features for users that will require a sign in, they can use an existing social login account (like google or facebook) or sign up for an Auth0 account specific to this site.
Docker
Containerization has been a big trend over the past few years, much like virtualization was the big trend before that. To oversimplify things, virtualization takes a whole server and runs it on a host simulating hardware. Containerization takes that a step further, where a container basically only has the pieces of an operating system needed to run an application (e.g. just a linux kernel) and runs that as a tiny process on a host server. This allows you to run applications with a much smaller footprint, allows easier separation/scaling of tasks, and gives you a nice way of tearing down/redeploying entire applications without worrying about server configs etc. I am using docker containers for each service on my production host. On my development machine I have a script that builds a docker container based on my compiled Go code, and pushes it up to a private repository on DockerHub. On the production host I have a script that stops and deletes the current running container and replaces it with the one from DockerHub matching the tag I specify. This allows me to deploy new versions of Digital Lethargia with only 5-10 seconds of downtime.
Git
For source code control and versioning I am using Git with a private repository hosted on GitLab. Source control allows you to clone a copy of your source code locally to work on. It keeps track of your changes and when they are ready, you commit them back to the reposity for deployment to your production environments. Since the changes are tracked, you can easily revert to previous versions anytime if something has broken, and you can create branches etc. to explore different ideas or features without disrupting regular work and fixes. It also allows multiple people to work on the same project at once, helping to identify and merge any conflicts that arise.
Linode
For my host I decided to go with Linode. Through work I have some experience with Amazon's AWS and Microsoft's Azure. While their prices are fairly competitive, and they offer free tiers (at least for a limited time), the storage and network transfer costs can sneak up on you. Linodes plans for hosted linux servers seemed reasonably priced with included storage and network transfer all as one line item. So far I am happy with the performance and management options, but have not pushed the system at all yet.
Changes commited since last Dev Diary
- Added max-width style to images for resizing on mobile
- Added published and security check to article view handler
- Added check for future publish date on article view
- Added local feed creation and editing
- Changed html sanitizer to allow code block style
- Fixed unused package import
References
- Golang: https://golang.org/
- Gin: https://gin-gonic.com/docs/introduction/
- GORM: https://gorm.io/docs/
- Auth0: https://auth0.com/
- Docker: https://www.docker.com/
- Git: https://git-scm.com/
- GitLab: https://about.gitlab.com/
- Linode: https://www.linode.com/
For this first development diary I am going to review some of the past items and false starts that have happened over the years before bringing this version of Digital Lethargia online. I think it will be a good way to document some history and put in writing some of the lessons I have learned.
My Background
I have been interested in computers since my family first brought home a Commodore VIC-20 in the early 80s. My sisters and I would play games as well as trying to enter programs in BASIC from magazines. This interest has stuck with me, and I eventually went to a technology institute to earn a diploma in computer technology. After that I spent 8 years working as a C/C++ developer on the Solaris and Windows NT platforms, with the past 12 years working as a Systems Administrator/Operations Analyst. I am a Linux enthusiast and also like to play video games, both on consoles and PC. You could probably accuse me of being stuck in the past to a certain extent as well...

Slackcrew.com
Some of my facts may be fuzzy from this time so cut me some "slack" if some things are incorrect, but sometime around the end of highschool and the start of college, some friends put together a website located at slackcrew.com. Before all the social media of today, it provided a place for my friends and I to share links, pictures, and our immature thoughts. At some point in 2002 the site got rewritten in PHP with a MySQL backend. It also started to incorporate some more modern ideas still used today like cascading style sheets. It is around this time I started to help out with the development a little bit. I wrote a new image gallery, calendar system, a stock ticker game, and helped out with other random items. The site continued as such until we finally closed up shop sometime around 2010 - 2011.

Digital-Lethargia.com
Around the time that slackcrew was shutting down, a group of us wanted to do a 24 hour gaming marathon for charity and needed a site to promote it. Since I didn't control the slackcrew domain myself, I decided to take one of my favorite tag lines for the site that my friend came up with (Digital Lethargia), and use that as a domain. It is a bit long and clunky as a domain name (Hence why you can now use www.diglet.ca), but I still like it. Since we needed something up quick, I threw together a template using SquareSpace (I was watching a lot of Revision3 at the time...) with the idea that I would develop something for the domain myself after the event was over. Thus began the next 10 years of false starts, rewrites, and letting life get in the way.
Revision 1: Drupal with custom PHP
My original thinking was that I did not want to write content management code from the ground up, so I looked around at the different content management systems out there and decided on Drupal because it seemed to offer more support for including custom PHP than Wordpress. This worked well as a starting point to getting a basic blogging system with a few custom pages up quickly. I even managed to get a new version of the stock ticker game from slackcrew (SlackTicker) integrated into Drupal. But getting the custom PHP code to actually fit into the Drupal security and themes always seemed to take much more effort on tasks that I really didn't enjoy. Eventually I stopped working on this version and never brought it online.
Revision 2: PHP with MySQL
The second attempt came when the feed aggregator I was using at the time shutdown and I couldn't find a new one that I really liked. So I started from scratch in PHP with a MySQL backend. I got the system to a point where you could add and manage RSS feeds. You could view each feed separately, or view them all merged into one stream ordered by the published date. You could mark the entries as read and it would hide them from your stream, or mark them as saved for later consumption. The backend would split the feeds up into 4 groups and update a group every 15 minutes. I actually used this as my own personal feed aggregator for around 2-3 years. The trap I fell into with this version was that I kept telling myself I would make it available to the public as soon as I got the user interface perfect, and got the other features implemented. But this was during a time where my life became fairly busy and did not leave much energy to put towards those features.
Revision 3: Golang with Angular
More recently, I am now back in a situation where I actually have some time for personal projects. I became interested in Google's golang as it allows you to do a lot of powerful things without a huge amount of code. It is aimed mostly for microservices, but you can use it for almost anything. I figured since Golang was more for services, I would use a separate front end framework running on a proper webserver, with Golang handling the API backend. The separate API would also allow other apps and services to talk to it without any extra development. A couple of our systems at work used Angular for their front ends and I really liked what I saw so I chose to write the front end in that. My main issue with this revision was trying to take on too many new things at once. I was learning both Golang and Angular, and got frustrated with the roadblocks I would hit. On the security side I was trying to use social media logins so that I would not be storing anyone's account info, so that meant learning the Oauth, and Java Web Tokens in both systems. I would fix something on one side that would end up breaking the other, which turned into an almost endless loop. Developing in this way meant I never really developed a good base of skills in either system.
Current Revision: Golang only
I will cover the specifics of this revision more in my next Dev Diary, but earlier this year I started again using just Golang. Golang has its' own built in webserver, plus many packages that extend upon that and add other features. I started with the roadblocks from my last attempt and was able to solve them with much less frustration by only using one framework. I now have the system up as a simple blogging system, with the aim of adding the features from revisions 1 and 2 in a more incremental approach.
Lessons Learned

Progress, not perfection
I am using one of my friend's favorite Denzel quotes as the name of this lesson. This has been (and continues to be) one of the hardest lessons for me to learn in life. I tend to be scared of showing things to people until I feel they are completely ready and feature complete. This also causes me to focus too much on the big picture of a project which is intimidating, and leads to procrastination. To combat this I am trying to learn and adopt more of a continous integration/continuous deployment approach, where things are broken up into much smaller features and deployed to production on a frequent basis.
Shorter but more frequent work sessions
Another mistake I would make would be to put off working on personal projects if I didn't have a whole afternoon or evening to dedicate to them. What I have been trying to this year is to sit down everyday for 30-60 minutes to do something productive for myself before getting sucked into TV or games. If I end up spending more time on it then great, or if during that 30-60minutes I don't get much done then that is ok as well. It doesn't have to be the same project everyday as I always have a couple of things on the go, but it is also important not to start too many things at the same time. The goal behind this is building habbits, and using my energy before the couch sucks it away. If I end up sitting in front of a project not doing much then I also have to recognize it is ok to stop there before getting frustrated and burnt out.
Proper Development environment and pipelines
When building things for personal projects, it is easy to just do all the work and testing in production. This makes it harder to identify and fix bugs, and puts up mental blocks against trying new ideas out. And of course leads to more disruptions to your production system. The tools today make it a lot easier to have a local dev environment, a staging test environment, as well as a production environment with deployment pipelines. In my next Dev Diary I will outline some of the tools I am using.
Thank you for your patience while I led you on this trip through the past with me. I imagine that future Dev Diaries will be shorter as the changes will be smaller and hopefully more frequent as time goes on.
-Lemac